
Blocking potentially fraudulent traffic by a set of rules has long been the standard practice in the advertising industry. Rules can be a rather effective way to mitigate fraud risks and give marketers a glimpse of protection by uncovering well-known patterns.
However, quite often rules-based anti-fraud solutions don’t keep up with the increasingly sophisticated techniques fraudsters use to exploit their advertising budgets: a pre-set of fixed thresholds that can be easily reverse-engineered wouldn't help you uncover unknown or emerging schemes and neither would they adjust to newer fraud patterns. All these drawbacks are impossible to ignore, especially if you calculate how much such errors of rules-based solutions can cost your advertising campaigns.
In this article, we’ll quickly summarize the key differences between rules-based models and Machine Learning (ML) algorithms in fraud detection. Our focus though, will be on shedding some light on real customer data of how app developers went the extra mile to cross-check the results provided by the seemingly trustworthy rules-based tools.
Rules-based anti-fraud technology
Rules-based anti-fraud solutions constitute a system with a set of predefined rules aimed to identify high-profile fraud patterns. A rules-based technology operates by analyzing specific parameters and flagging out those that fall outside the “standard” range.
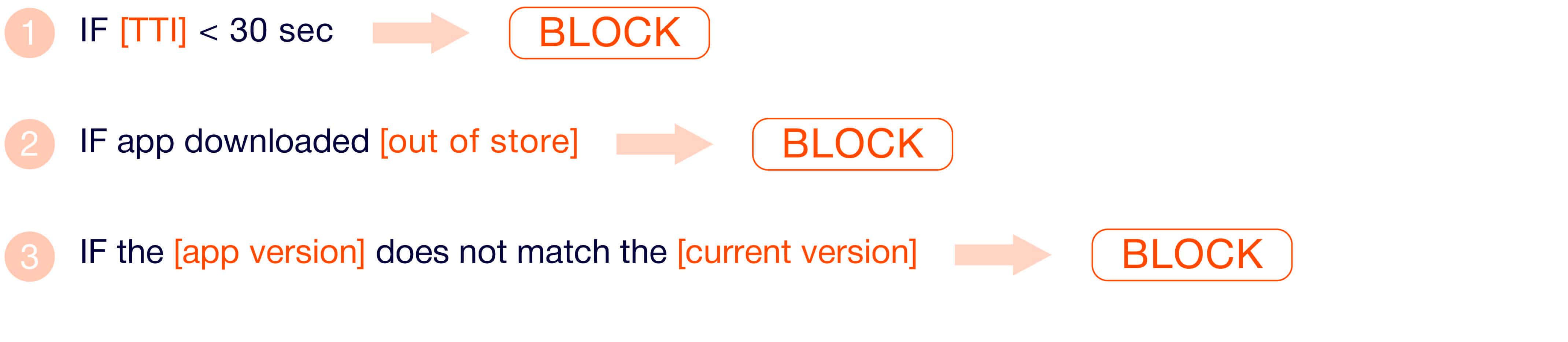
- IF [TTI] < 30 seconds ⇨ BLOCK
For instance, you know the “normal” TTI (Time-to-Install) parameter ought to be more than thirty seconds. In this case, all installs that had less than thirty seconds between ad click and app install/first open would be marked as click injection. But this rule can't be used as trustworthy for two reasons:
1) It leads to false positive results since each country has different Internet speed, apps have a different size at the app stores, etc. Hence, sometimes the TTI may be less than thirty seconds for real users.
2) This rule also misses out part of fraudulent installs, since fraudsters can't affect the time of the first opening of the app and the fraudulent install may occur after thirty seconds.
- IF app downloaded “out-of-store” (Google or Apple) ⇨ BLOCK
Another example that is commonly used in rules-based systems is the “out-of-store download” parameter. The issue is that conventional anti-fraud solutions often block installs that don’t boot from primary app stores - such as Google Play Market and Apple Store. This rule leads to false positive results, since apps can be downloaded from less popular app stores or using an APK file.
- IF the [app version] does not match the [current version] ⇨ BLOCK
The downloaded version of an app gets compared against that of the primary app store and an install is rejected if it doesn’t match. However, this approach has a crucial drawback: some developers may neglect to adjust their apps for all app stores, and sometimes also don’t update app versions designed for older devices. Thus, leading to false positive rejected installs.
Generally, rules-based anti-fraud solutions are able to detect well-known types of fraud. What’s more, they are reasonably successful at rejecting fairly primitive fraud in real-time. At the same time, fraudsters can easily reverse-engineer basic rules, so a rules-based technology requires regular updates while also being unable to perform post-install analysis, which makes it impossible for them to identify - let alone prevent - sophisticated fraud, such as Smart Bots, Mixes or Device Farms. All that can yield false positive results and, subsequently give a client a misleading impression of being protected from fraudsters.
Is following the rules the best idea when it comes to fraud detection?
Now that we have clarified the principles of a rules-based solution let’s have a look at real-life examples to make a judgment whether this approach is effective in detecting fraud.
A bright example of how utilizing a rules-based fraud protection tool could ruin your business is the number of false positives and false negatives that can occur.
One of our clients proceeded to analyze traffic using both (a rules-based technology which was in place prior and Scalarr’s ML-based technology) services simultaneously and found the results to be utterly shocking:
The rules-based model blocked 34,000 fraudulent installs, whereas the ML algorithm flagged 43,000. Meanwhile, the overlap was minimal (roughly 2,000 installs), meaning that the ML model identified fraud in traffic that the rules-based solution marked as non-fraudulent and vice versa. The number of false results was 73,000 installs (32,000 of false positive and 41,000 of false negative errors).
A bright example of how utilizing a rules-based fraud protection tool could ruin your business is the number of false positives and false negatives that can occur
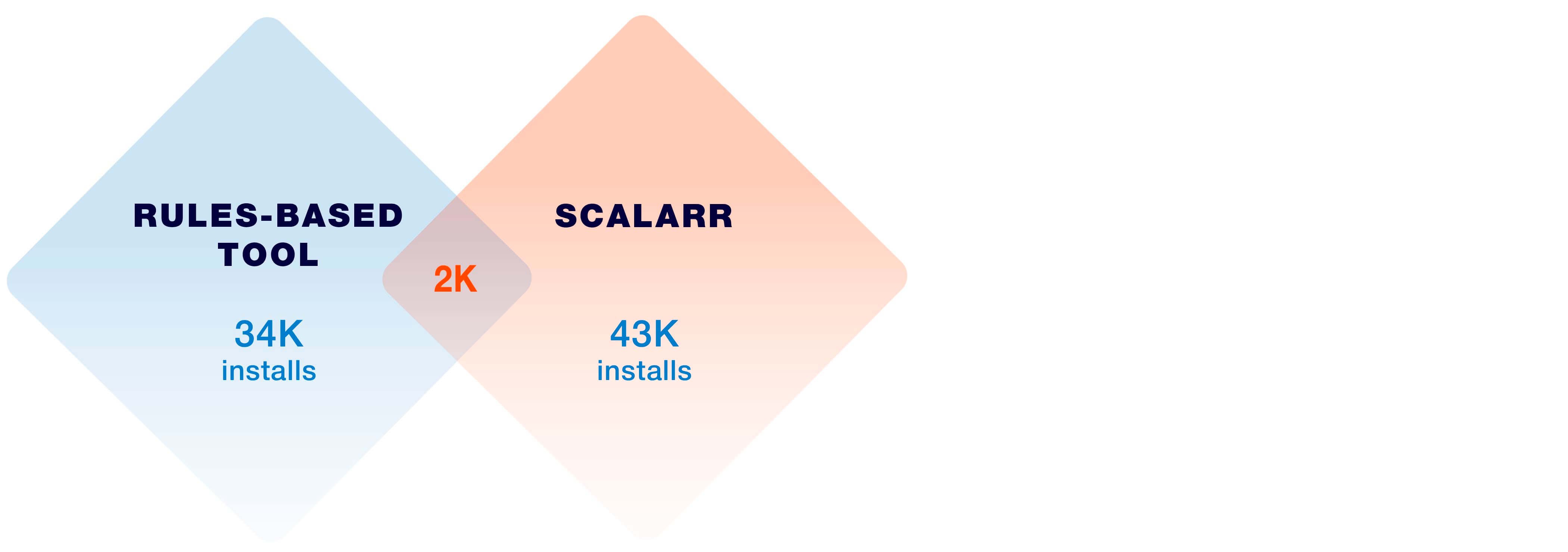
This means that the client rejected real users and kept paying for fraudulent installs. While the results of both solutions look very similar on the surface and the savings are comparable, the main point of having an anti-fraud solution in place was completely missed.
Moreover, the results that were provided by the rules-based technology were misleading the client as to which sources are actually delivering high-quality users. As you can see below “Network B” seems to be a good source when looking at the rules-based results whereas when looking at the ML-based technology this source has delivered over 90% of fraudulent installs.
So not only would the client keep paying for fraudulent installs and reject real ones, but they will also rely on and scale sources that are low performing but appear to be highly profitable.
| Publisher | Rules-based tool | Scalarr | Intersection |
| Network A | 7580 | 1340 | 76 |
| Network B | 392 | 22980 | 0 |
| Network C | 1340 | 0 | 0 |
| Network D | 2423 | 345 | 0 |
| Network E | 9852 | 29 | 0 |
| Network F | 12237 | 15867 | 1928 |
| Network G | 0 | 2458 | 0 |
| Network H | 252 | 0 | 0 |
Now, let’s take a closer look at the biggest dependencies in the analysis.
1. When false positives are shockingly frequent
The rules-based tool has identified and blocked 21,000 installs that fell within the basic rule called TTI (time to install) Outliers. In this case, we see the use of the rule when all installs that had more than 24 hours between ad click and app install/first open are marked as click spam. However, after performing a deep retrospective analysis, Scalarr’s tool detected that this traffic was a pre-installs, for which the TTI distribution when the installs coming after 24 hours is natural. So it was not fraudulent traffic.
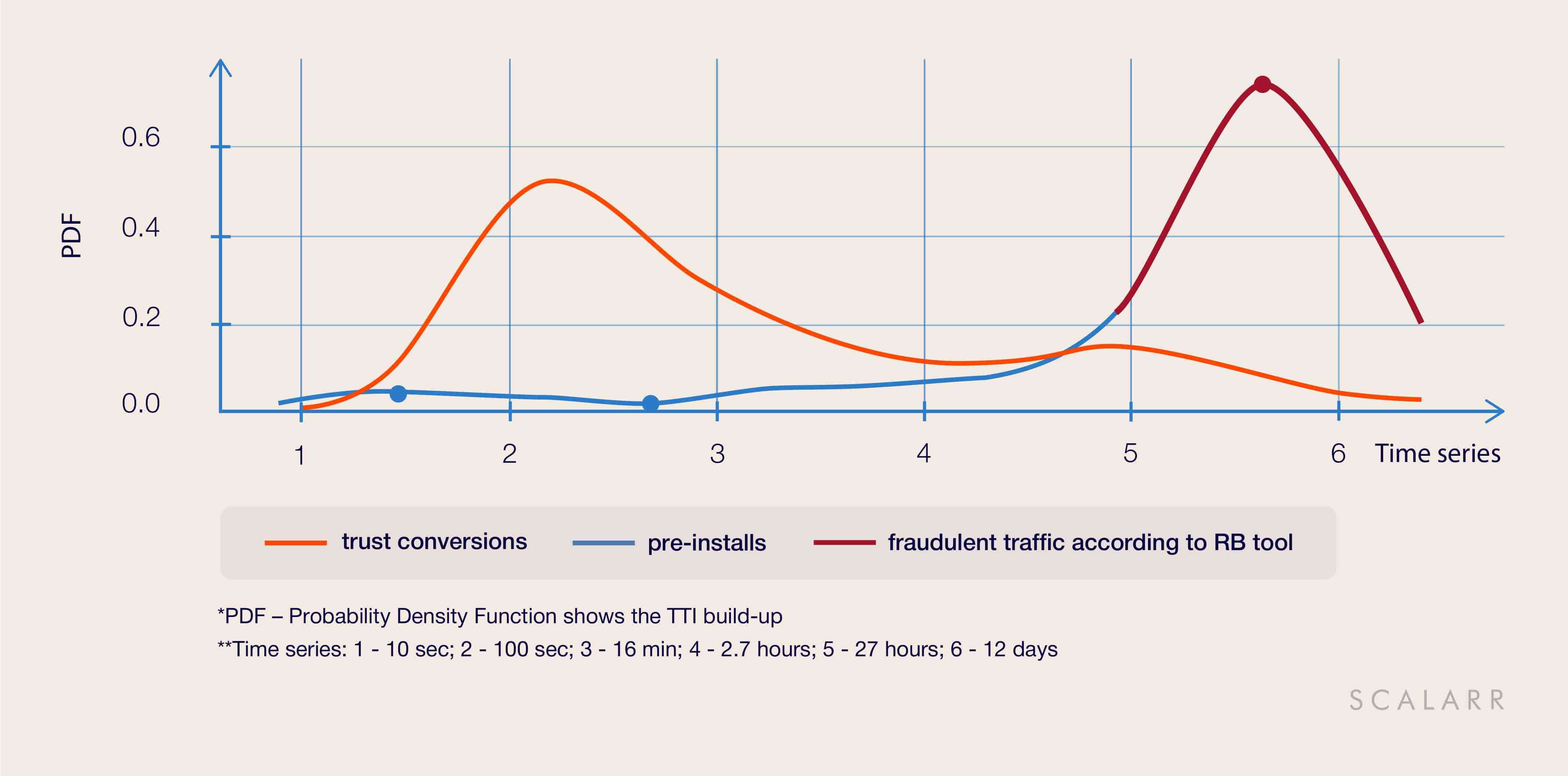
Furthermore, we found out that some part of blocked installs were, in fact, a part of the customer’s cross-promotion campaign - the rules-based tool blocked installs coming from another client’s app. This is a glaring example of the negative impact of false positives.
2. Why do fraudsters fly under the radar?
App X, one of our current customers, used a rules-based solution to mitigate app install fraud prior to working with us. After performing a historical traffic analysis and comparing results, we found out that the rules-based solution neglected 100% of fraudulent installs and failed to block them. The reason is that the algorithm of that rules-based solution was only equipped to reject installs in real-time, and hence couldn’t analyze post-install activity.
In this case, we are looking at Smart Bots - the type of fraud that emulates an abnormally high number of events (app open, level one complete, tutorial complete) to remain undetected. Nevertheless, Scalarr’s ML system was able to filter out fraudulent installs as you can see in the next graph.
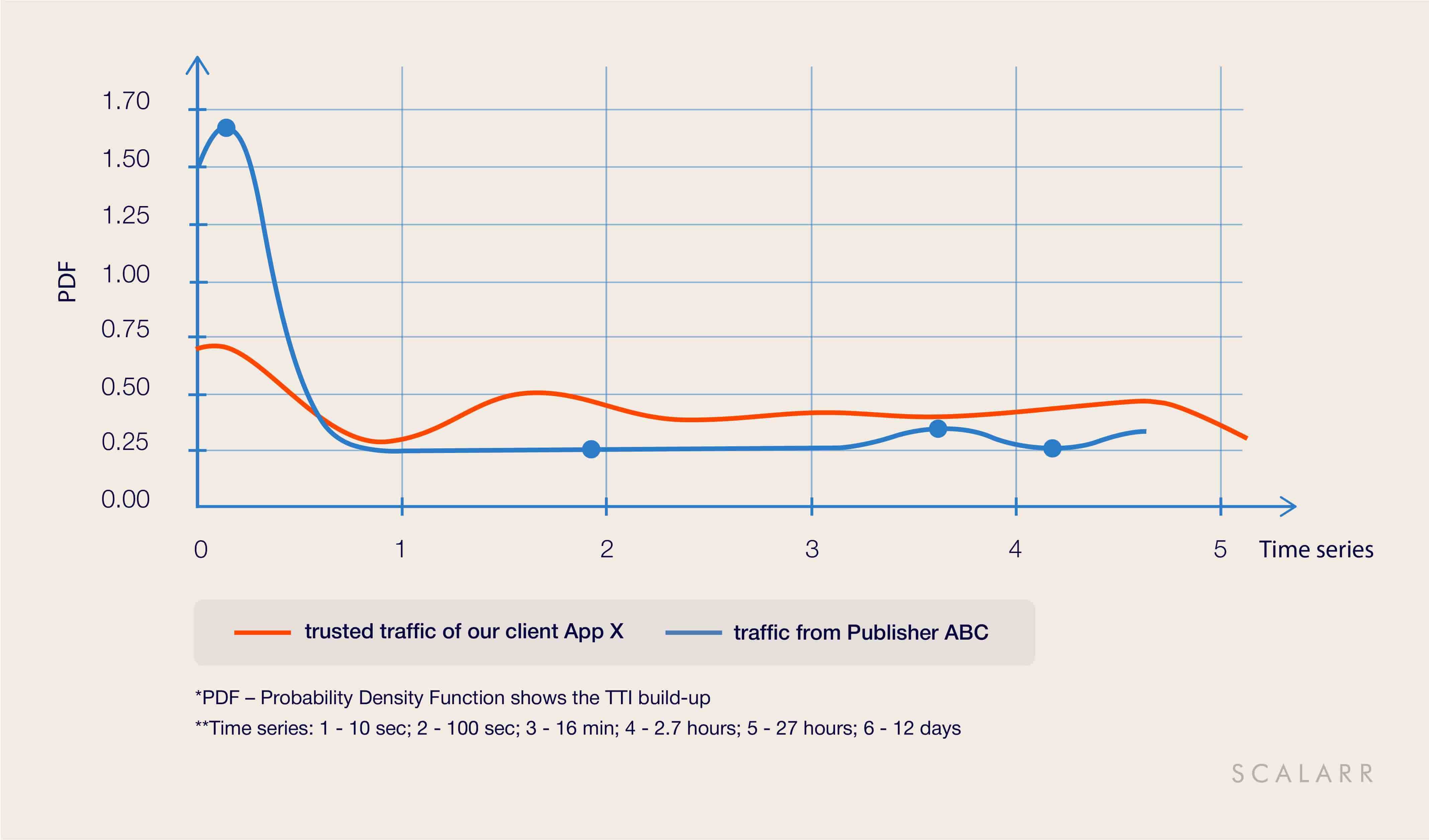
The rules-based model blocked zero installs from this publisher, assuming it’s all human traffic. With these high engagement rates, the publisher in question would be the desired source for any User Acquisition manager. However, stayed undiscovered, this would have resulted in significant losses of our client’s marketing budget.
Machine Learning to the rescue
ML (Machine Learning)-based anti-fraud solutions are advanced tools that leverage Machine Learning algorithms alongside Big Data to analyze app install traffic. The main difference of ML-based tools in respect to rules-based solutions is that the former ones are more sophisticated and don’t set any rules for detecting specific fraudulent patterns.
The merit of ML-based anti-fraud solutions is evident when it comes to specific metrics. Consider the time-ordered distribution of user behavior, for example. Let’s take the cohort of downloads where all hardware metrics are genuine - i.e., a real device with a unique device ID, IP, and TTI that mimics real user behavior. A rules-based solution will define such installs as non-fraudulent by default. At the same time, the analysis of the same cohort with the ML-based solution would reveal anomalies in the time it takes a user to reach the next level within the game.
This example follows the actual experience of one of Scalarr’s customers - a major game developer, who was using our service alongside a rules-based solution. The anomalies in the app’s traffic were detected on the post-install level: while “human” users take anywhere between five and ten minutes to progress to a certain level in the game, in a fraudulent cluster this level was achieved within just twenty to forty seconds. The ML algorithm identified the discrepancy and marked installs as fraudulent, despite hardware metrics looking completely real.
Here’s why a rules-based solution was unable to provide the desired outcome:
- First things first, all hardware metrics were perfectly forged by fraudsters.
- The setup of the “behavioral” rule ( time to reaching a certain level) requires having the “right” parameters, which in this case can vary over a wide range for each particular install.
By contrast, a Machine Learning algorithm analyzes data by breaking it into cohorts (or clusters) and compares every single cohort against that of real user behavior. It then calculates the probability and deviation degree to identify significant anomalies and detect fraudulent traffic.
Ultimately, ML-based anti-fraud solutions are capable of providing well-rounded protection against well-known and emerging types of app install fraud. Thus, producing clear outputs with actionable data, personalized for each specific app.
Wrapping it up
After all, using a rules-based anti-fraud solution can be a first of defense against primitive types of fraud, such as classic and modified click spam. Rules-based models are designed to do just that - you set the rules and installs that fall within them are rejected automatically. Using rules-based solutions alone could potentially result in a high rate of false positive and false negative errors, screwing up advertising campaign’s data and harming your business.
Fraudster’s techniques are undoubtedly evolving, and marketers need increasingly more sophisticated approaches to confront them. That’s exactly where Machine Learning comes in handy: modern ML algorithms are capable of automatically discovering and learning new fraud patterns without any data labeling or training, thus making it possible to detect even the most sophisticated types of fraud with high accuracy. Add to that the possibility to personalize an algorithm for each app, and it becomes clear why ML-based anti-fraud solutions can detect even the latest and most insidious types of fraud, including Smart Bots and Device Farms.
Want to know more about Machine Learning for fraud detection? Drop us a line!
The only solution for mobile advertisers is to partner with anti-fraud tools that make use of powerful and intelligent technologies such as machine...
The road to Scalarr's foundation was paved with challenges and opportunities and in this in-depth conversation, you'll learn the story of Scalarr f...